Approach
Our goal is to extract a universal, scale-robust visual representation from a frozen Vision Foundation Model (VFM). The core of MuRF is motivated by a fundamental property of visual perception: low resolutions capture global context for robust recognition, while high resolutions provide fine-grained detail for precise refinement.
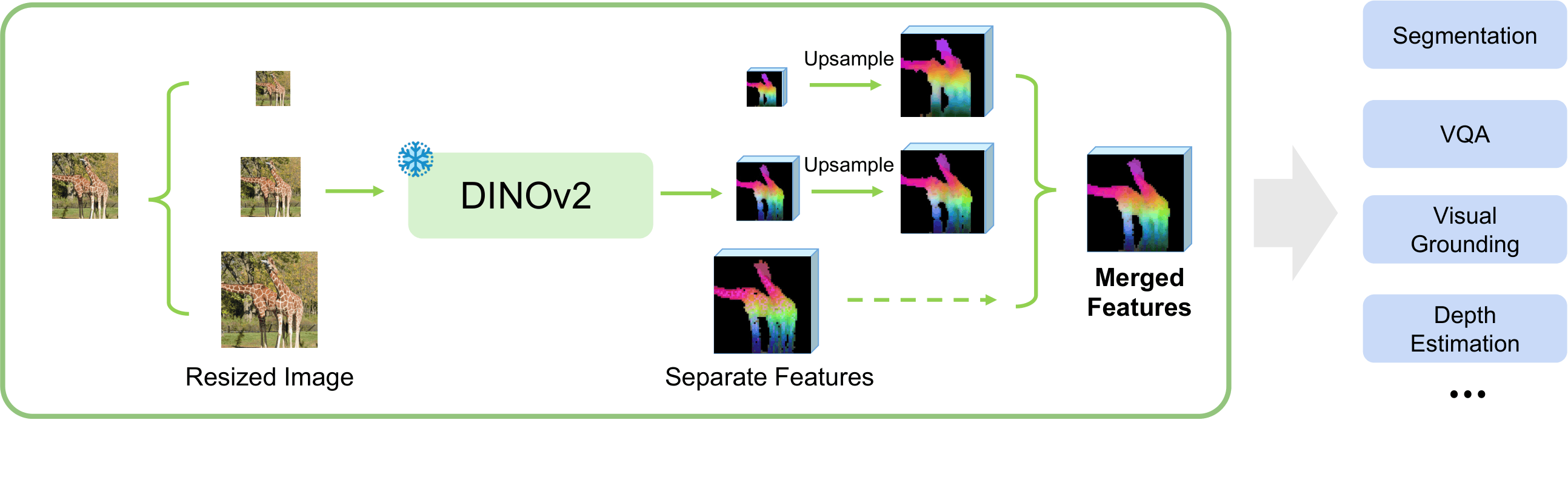
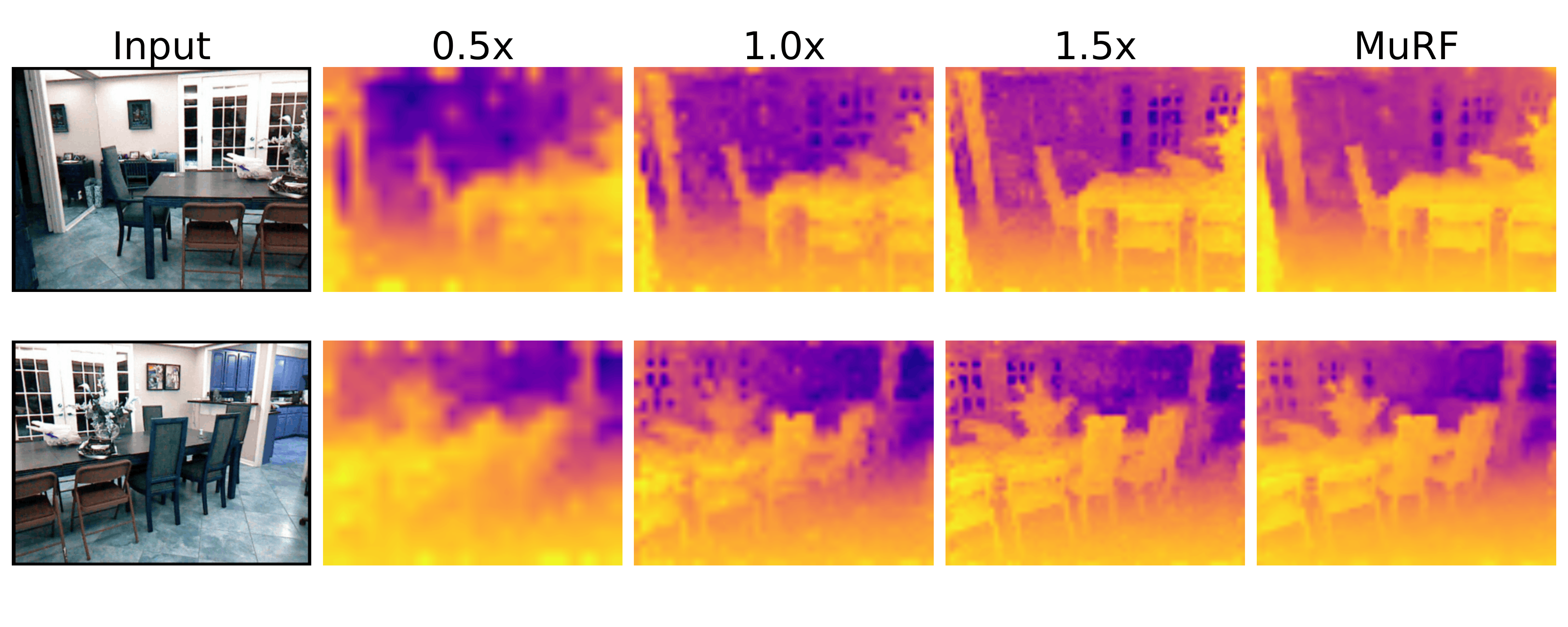
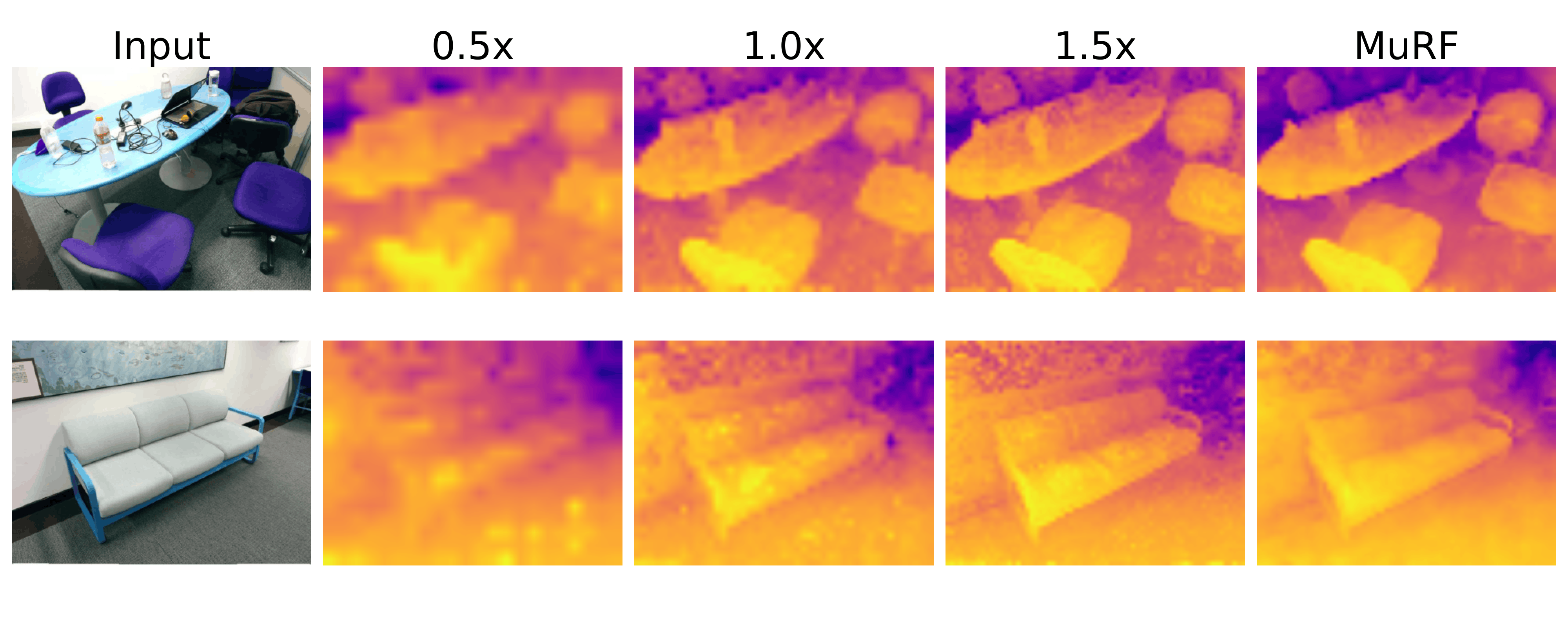
Overview of Multi-Resolution Fusion (MuRF). We process an image pyramid through a frozen VFM, upsample the resulting feature maps to a common spatial resolution, and concatenate them channel-wise.
Multi-Resolution Feature Fusion
MuRF builds a feature pyramid directly from the input space. We resize the image to a set of scaling factors and pass each view through a frozen VFM encoder.
Crucially, these patch-level feature maps are upsampled to a target spatial resolution and concatenated along the channel dimension. This creates a single, unified tensor that is spatially rich, semantically deep, and explicitly preserves the orthogonal signals of both macro and micro views without the destructive interference caused by mean-pooling or summation.
Task-Specific Adaptation
The resulting multi-resolution representation is inherently task-agnostic. We adapt it to various domains by attaching lightweight, task-specific heads while keeping the heavy VFM backbone completely frozen:
- Dense Prediction: For tasks like semantic segmentation and depth estimation, we apply a simple convolutional head (e.g., a 1×1 convolution) to project the concatenated channels directly to the target output space.
- Multimodal LLMs: For Visual Question Answering (VQA), the MuRF tensor acts as the visual token sequence, passed through a lightweight perception module into the language model's word embedding space to enable multi-scale reasoning.
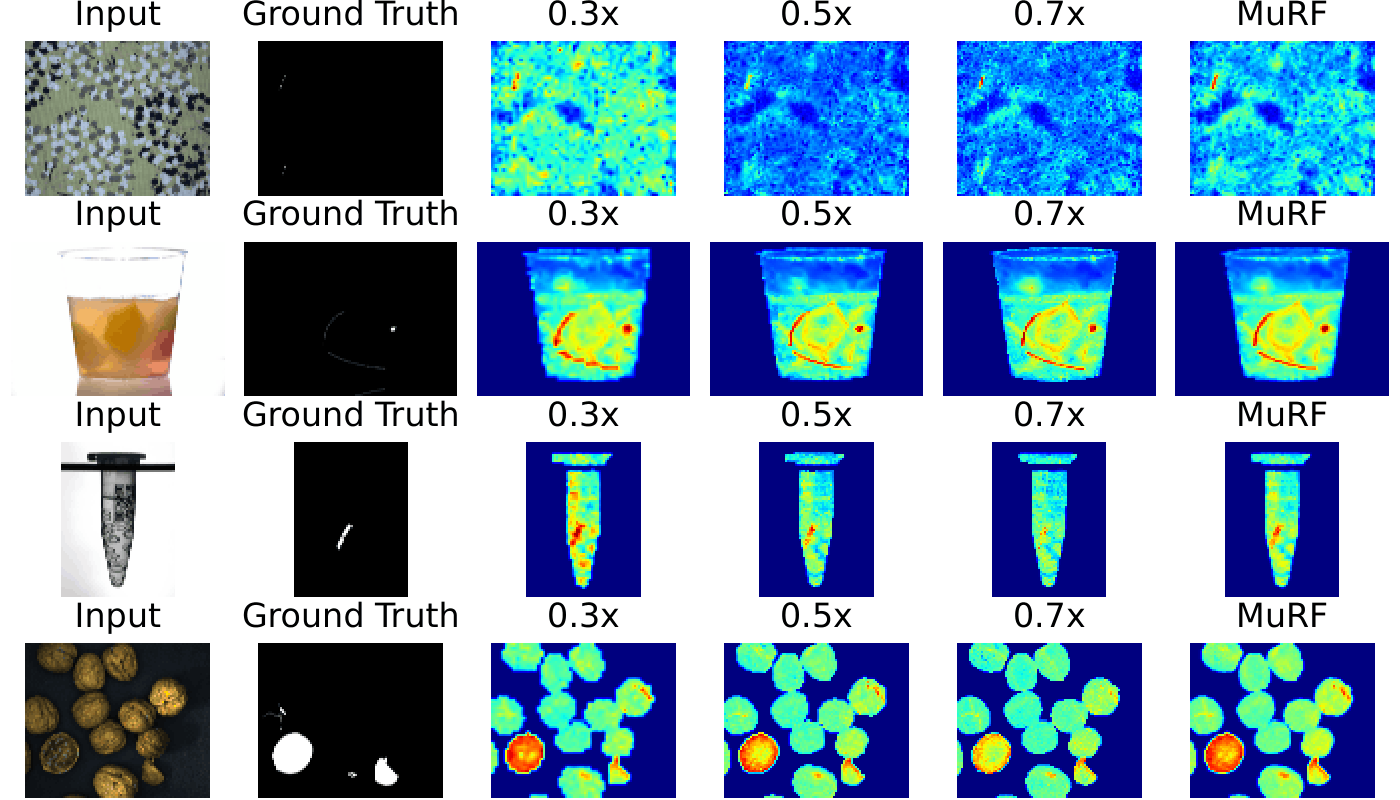
- Unsupervised Anomaly Detection: We utilize a training-free nearest-neighbor approach, building memory banks across layer-resolution pairs and averaging the resulting distance scores to leverage the strengths of all views.